Fake Job Postings: How Machine Learning Can Protect Job Seekers
Every year, thousands of people fall victim to fake job postings. Scammers impersonate real companies, promise high pay for “data entry” or “work from home” roles, and collect personal information or upfront fees from job seekers who are genuinely trying to find work.
The dataset used here contains 17,880 job postings from a real employment platform. Only 866 of them are fraudulent – about 1 in 20. The goal: build a model that can flag fake postings automatically, before a real person gets hurt.
The Challenge: Extreme Imbalance
The biggest problem with this dataset is not complexity – it is proportion. There are 19.6 real postings for every 1 fake posting. A model that simply labels everything as “real” would be correct 95% of the time. That sounds good, but it would miss every single fraud case.
This is why accuracy is the wrong metric here. Instead, we track:
- Recall: Of all actual fake postings, how many did we catch?
- Precision: Of the postings we flagged as fake, how many actually were?
- F1 score: The balance between the two.
- PR-AUC: The overall quality of the model across all decision thresholds.
To handle the imbalance, every model was trained with a class weight of 19.6 – making each fake posting count as much as 19.6 real ones during training.
The Data: What We Know About Each Posting
Each job posting includes both text fields (title, company profile, description, requirements, benefits) and metadata (whether the company has a logo, whether questions are asked, employment type, industry, required education).
From these, 19 features were engineered:
| Type | Examples |
|---|---|
| Text stats | Word count, text length, caps ratio, exclamation count |
| Presence flags | Has salary listed, has company profile, has department |
| Suspicious signals | Contains URL, contains phone number pattern |
| Categorical | Industry, function, required experience, education |
All text fields were also combined into a single document per posting for the NLP models.
Three Models, Three Approaches
Model 1: Logistic Regression on TF-IDF
The simplest approach: convert each posting’s full text into a matrix of 15,000 word and phrase frequencies, then train a logistic regression with balanced class weights.
This is a strong baseline. It reads the actual words and phrases in a posting and learns which ones are statistically more common in fake postings versus real ones.
Model 2: LightGBM on Tabular Features
A gradient-boosted tree model trained only on the 19 engineered metadata features – no text. This tests whether we even need to read the posting content to detect fraud.
Model 3: Sentence Transformers + LightGBM
The most advanced approach. Instead of counting words, a pre-trained transformer model (all-MiniLM-L6-v2) reads each posting and converts it into a 384-dimensional vector that captures meaning, not just frequency. These semantic embeddings are then combined with the 19 tabular features and fed into LightGBM.
Finding 1: Text Beats Metadata
The tabular-only model (no text) scored the lowest F1 of all three approaches. Metadata alone – whether a company has a logo, what employment type is listed, what industry is selected – is not enough to reliably detect fraud.
The moment we add text, performance jumps. Both the TF-IDF logistic regression and the sentence transformer model significantly outperform the metadata-only approach.
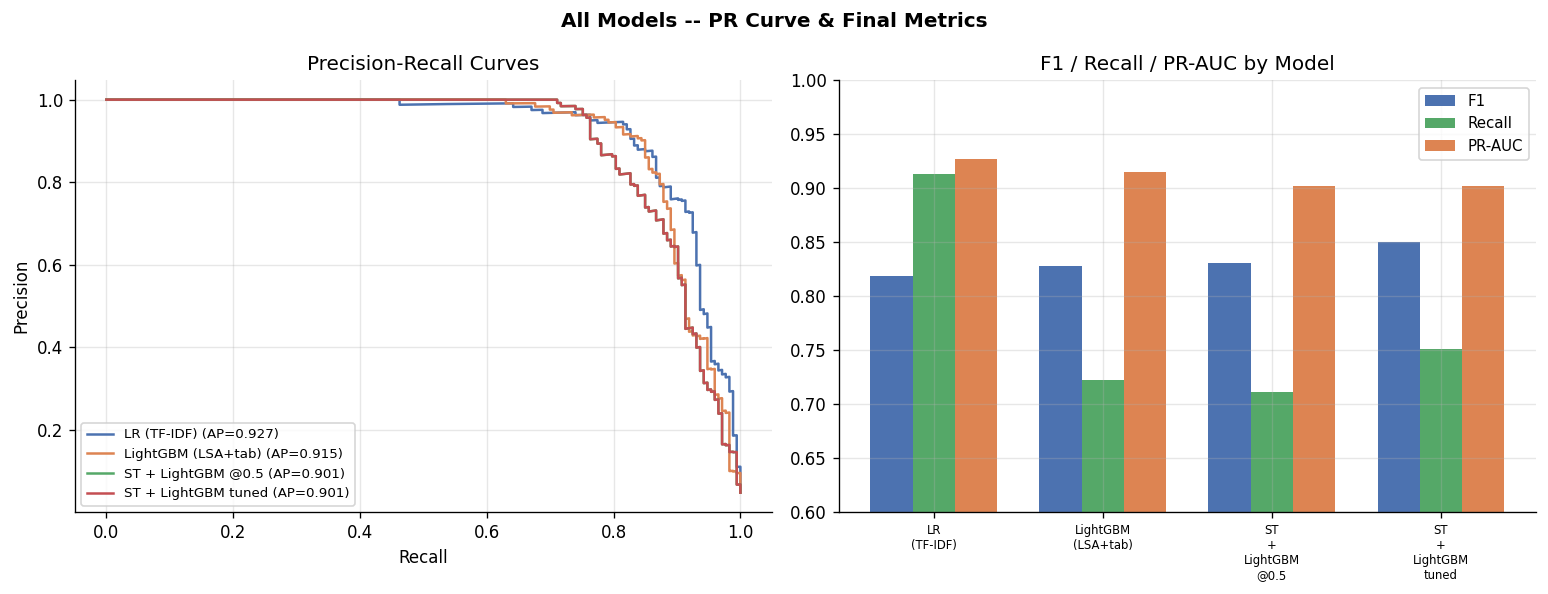
Why? Scammers can easily fake metadata. They can create a profile with a logo, select “Full-time” and “Engineering,” and pick a legitimate-sounding industry. But the language they use in the actual job description – “earn money from home,” “no experience needed,” “tax free income” – is much harder to disguise.
Finding 2: The Default Threshold is Wrong
Every classifier outputs a probability between 0 and 1. By default, anything above 0.5 is labeled “fake.” But with a 19:1 imbalance, the model learns to output very low probabilities for most postings. The default threshold of 0.5 is too conservative.
By testing every threshold from 0.10 to 0.90, the optimal point for the sentence transformer model was found at threshold = 0.10.
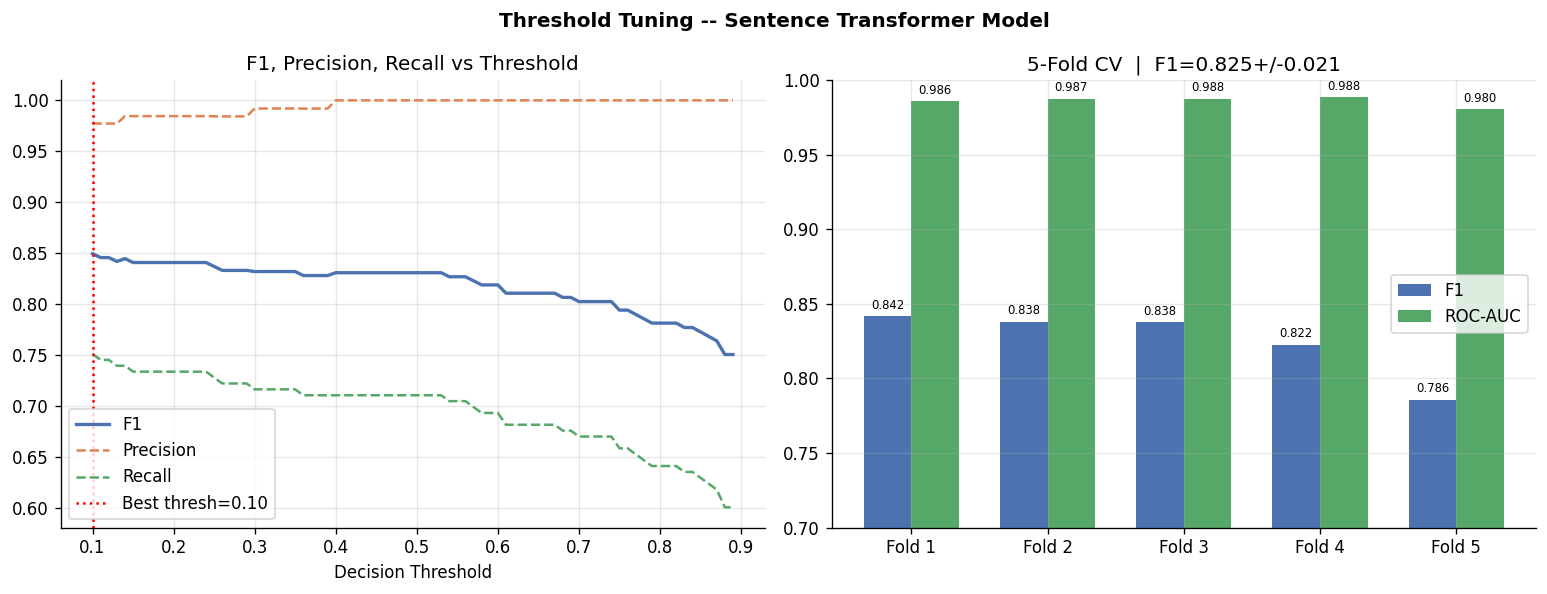
At this threshold:
- F1 improved from 0.831 to 0.850
- Recall improved from 71% to 75%
- Precision remained very high at 98%
In plain terms: at the tuned threshold, when the model flags a posting as fake, it is correct 98% of the time. And it catches 75 out of every 100 actual fake postings.
Finding 3: Fake Postings Have a Distinctive Language
Using log-odds analysis on unigrams and bigrams, we can identify the words that appear disproportionately in fake versus real postings.
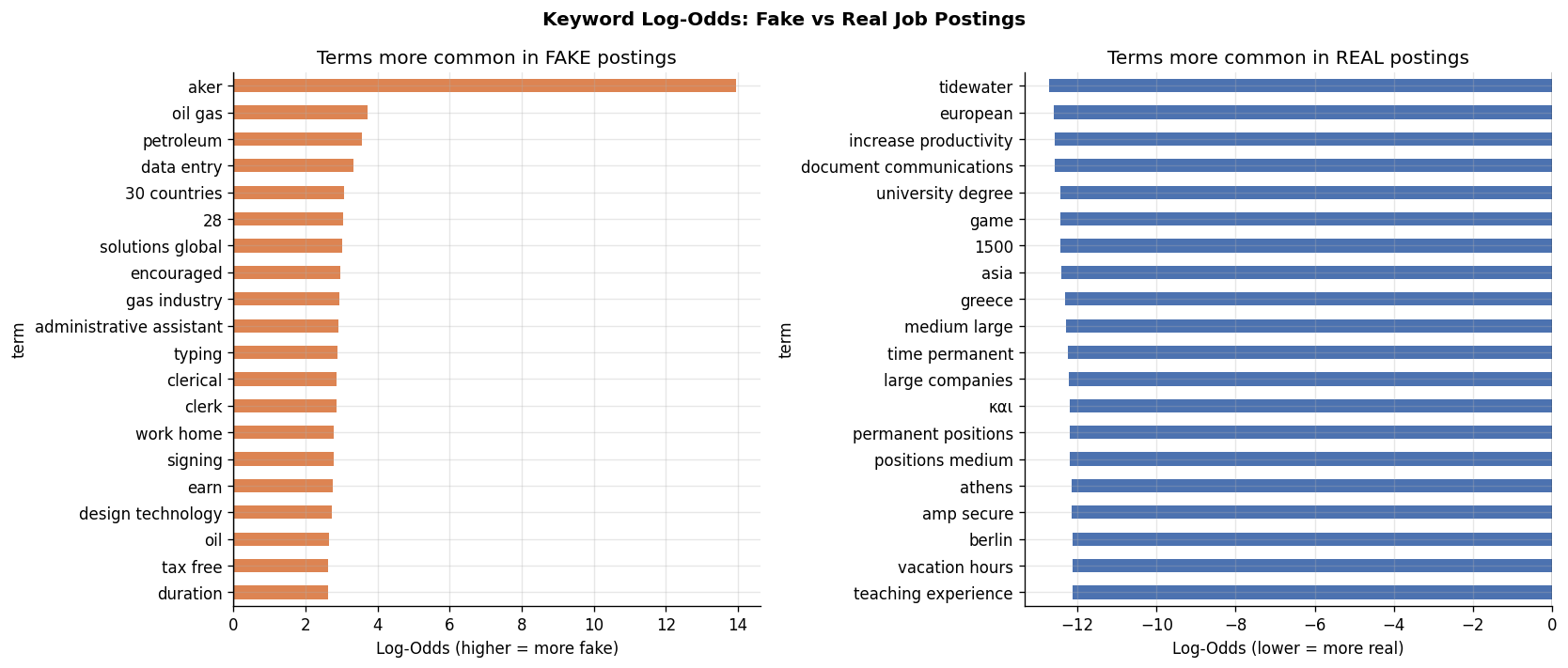
Words that signal fake postings:
- “work home,” “earn,” “tax free,” “typing,” “data entry,” “clerk”
- “oil gas,” “petroleum,” “gas industry” – a cluster of postings impersonating energy companies
- “30 countries,” “solutions global,” “duration” – vague promises of international reach
Words more common in real postings:
- Specific locations: “athens,” “berlin,” “greece”
- Academic language: “university degree,” “teaching experience”
- Legitimate operational terms: “permanent positions,” “large companies”
The pattern is clear: fake postings use emotional and aspirational language (“earn,” “tax free,” “work from home”), while real postings are specific about place, qualifications, and structure.
Finding 4: What the Model Uses to Decide
SHAP (SHapley Additive exPlanations) values show how much each tabular feature contributes to the model’s prediction. Higher values mean the feature has a larger effect on whether a posting is flagged.
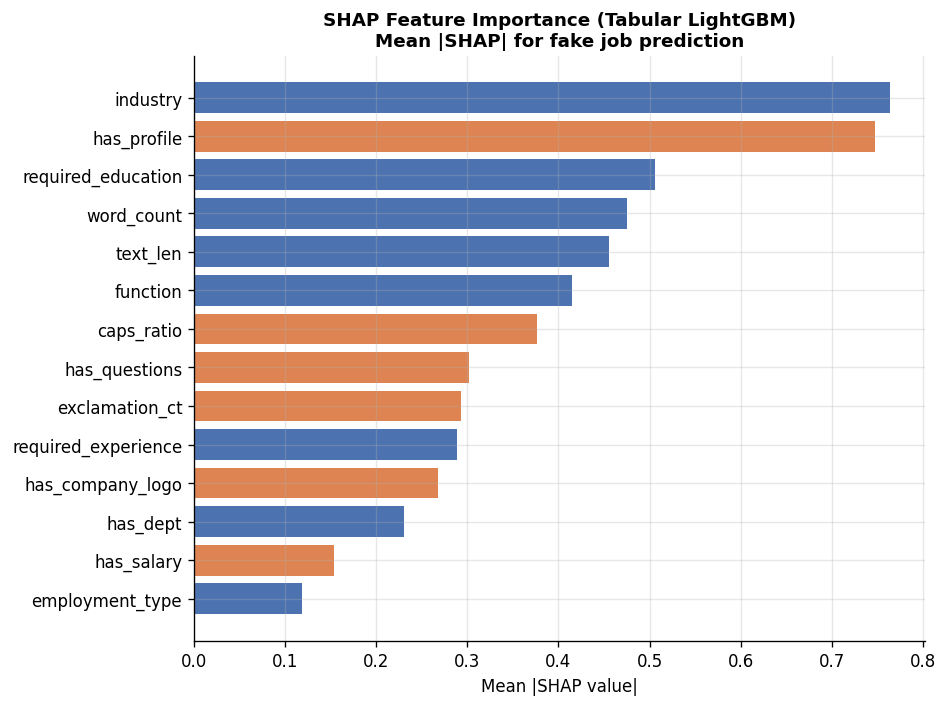
The top drivers:
- Industry – the industry category selected for the posting is the strongest signal. Fake postings cluster in specific industries that scammers impersonate.
- Has company profile – real companies almost always fill in their profile. Missing profile is a strong fraud indicator.
- Required education – fake postings often skip this or set it to “unspecified.”
- Word count and text length – fraudulent postings tend to be shorter or use padding differently from real ones.
- Caps ratio and exclamation count – excessive capitalization and exclamation marks are a measurable red flag.
has_company_logo – often cited as the key signal in fraud detection – ranked only 11th. The richer context from text and structural features matters more.
Cross-Validation: Results Hold Across Folds
To confirm the results are not a product of one lucky train/test split, 5-fold stratified cross-validation was run on the full dataset using the tuned sentence transformer model.
| Fold | F1 | ROC-AUC |
|---|---|---|
| 1 | 0.842 | 0.986 |
| 2 | 0.838 | 0.987 |
| 3 | 0.838 | 0.988 |
| 4 | 0.822 | 0.989 |
| 5 | 0.786 | 0.980 |
| Mean | 0.825 ± 0.021 | 0.986 ± 0.003 |
The ROC-AUC is remarkably stable across all five folds (0.003 standard deviation). F1 varies slightly more, which is expected given the small number of positive examples in each fold (~173 per test set). The model is not overfit.
Final Model Comparison
| Model | F1 | Recall | PR-AUC |
|---|---|---|---|
| LR (TF-IDF text only) | 0.819 | 0.913 | 0.927 |
| LightGBM (metadata only) | 0.828 | 0.723 | 0.915 |
| ST + LightGBM (default threshold) | 0.831 | 0.711 | 0.901 |
| ST + LightGBM (tuned threshold) | 0.850 | 0.751 | 0.901 |
If the goal is to catch as many fakes as possible (highest recall), the simple TF-IDF logistic regression wins – it catches 91% of fraudulent postings. If the goal is highest overall F1, the tuned sentence transformer model wins.
Both are valid choices depending on the product decision: prioritize catching more fraud at the cost of more false alarms, or flag less but with very high confidence.
Three Takeaways
1. Read the text. Metadata fields (logo, questions, employment type) are easy for scammers to fake. The actual language used in a job description is far harder to disguise. Any fraud detection system that ignores text is leaving most of the signal on the table.
2. Set your threshold deliberately. The default 0.5 threshold is wrong for any severely imbalanced problem. In this case, 0.10 was optimal. This is a business decision – how much do you weigh the cost of missing a fake posting versus the cost of wrongly flagging a real one?
3. Scammers cluster around recognizable patterns. “Oil and gas,” “data entry,” “work from home,” “earn money” – these are not random. Scammer communities share templates. A model trained on historical fraud will generalize well because the playbook does not change quickly.
Methodology notes:
- Dataset: 17,880 job postings, 866 fraudulent (4.8%). Source: Employment Scam Aegean Dataset (EMSCAD).
- Train/test split: 80/20 stratified by target.
- Class imbalance handled via
scale_pos_weight=19.6(LightGBM) andclass_weight='balanced'(Logistic Regression). - Sentence embeddings:
all-MiniLM-L6-v2via sentence-transformers, 384 dimensions. - SHAP values computed on a 200-sample stratified subset of the test set.
- Keyword log-odds computed on full training corpus using CountVectorizer bigrams.
Code & Data: View the analysis scripts here